한국시간으로 9월 2일 새벽 1시에 Nvidia의 새로운 RTX 아키텍쳐 Ampere에 기반한 그래픽카드 3종을 새로 발표했습니다.
여러 가지 변화점들도 있고 그래픽카드 외에도 새로 발표한 내용들이 더 있지만, 관심이 가는 부분만 중점적으로 정말 주관적으로 발표를 해석해보겠습니다!
1. 90 라인업의 등장
2018년 8월에 공개된 바로 전세대 라인업인 20 라인업의 발표 때는,
2080 Ti, 2080, 2070이 발표 되었습니다.
하지만 이번에는 3090, 3080, 3070을 발표했는데요.
90 라인업이 나올것이라는 의견은 출시 전부터 많이 루머로 있던 내용이지만, 실제로 이 90 라인업이 기존의 Ti 라인업을 대체하여 더 높은 성능을 강조하는 네이밍이 되는 것인지, 아니면 추후에 Ti 라인업을 따로 발표할 계획인지는 더 지켜봐야 할 것 같습니다.
확실히 Nvidia에서 Super라는 네이밍도 사용한 만큼 네이밍의 정리를 하려는 시도로도 해석해 볼 수 있을 것 같습니다.
2. 확실한 성능 향상

일단 쿠다 코어의 갯수에서 엄청 놀랐는데, 제가 알던 그 쿠다 코어 갯수가 맞나..? 의심이 될 정도입니다.
왜냐하면 바로 전 세대인 20 라인업을 보면,

전 세대 라인업 중에서 가장 좋은 그래픽카드였던 2080 Ti의 경우에도 4352개의 쿠다 코어를 가지고 있었거든요.
3070을 보면 5888개의 쿠다 코어 탑재로 확실히 성능 향상의 폭이 많이 느껴집니다.
다음 발표 자료를 보시면 비교가 쉬울 것 같은데요.
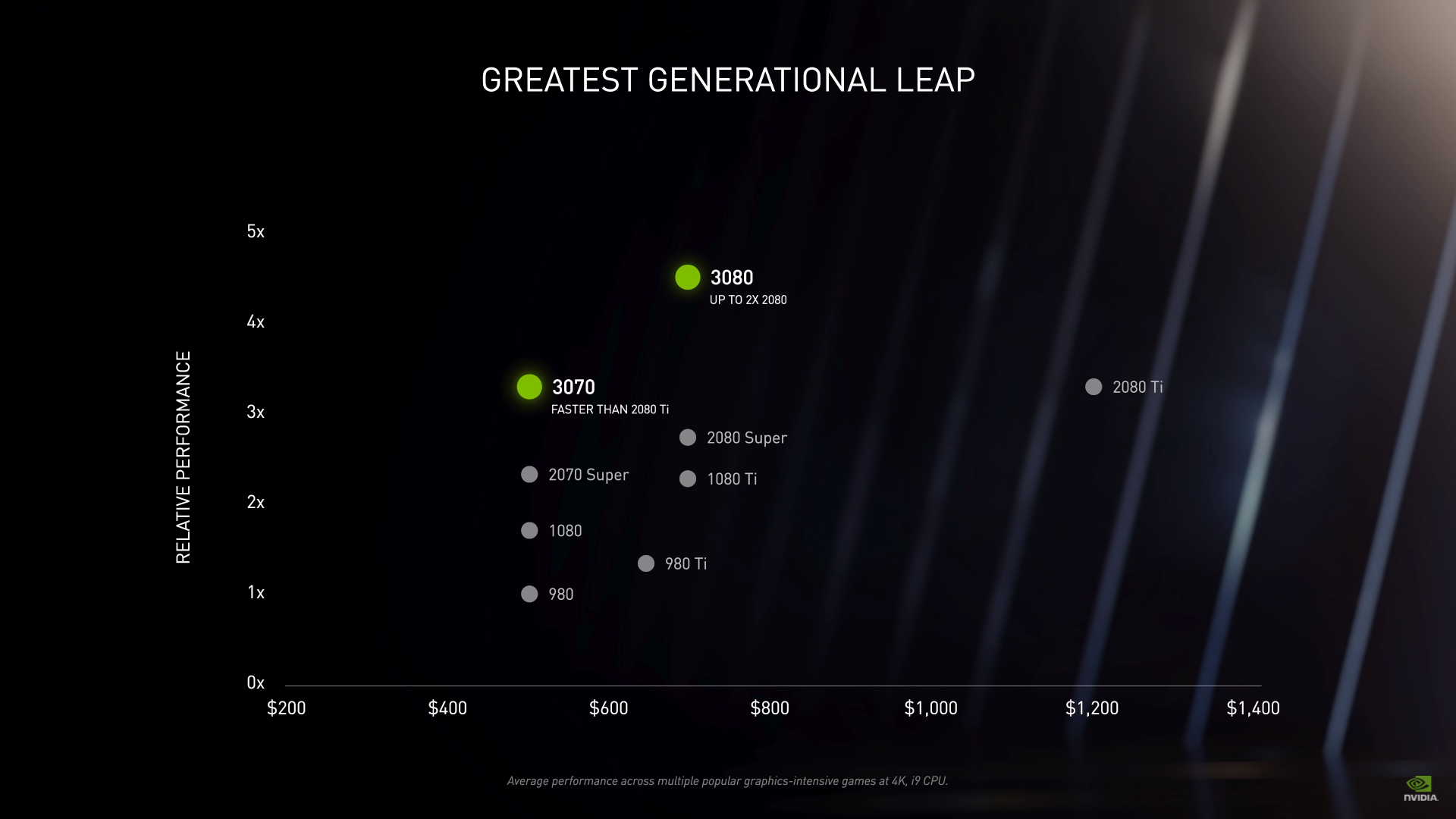
아쉽게도 3090의 비교는 나와있지는 않은데요, $499에 전 세대 가장 최강인 2080 Ti를 능가하는 그래픽카드를 살 수 있다는 것은 Ampere 아키텍쳐가 소비자의 입장에서 충분한 구매 메리트를 가지고 있다고 생각했습니다.
참고로 3090은 $1,499, 3080은 $699, 3070은 $499의 가격으로 출시됩니다.
마지막으로, 3090의 경우에는 Titan RTX랑 비교를 해봐도 좋을 것 같다는 생각이 들었습니다.
| Titan RTX | RTX 3090 | |
| 아키텍쳐 | Turing | Ampere |
| 쿠다 코어 | 4,608 | 10,496 |
| 텐서 코어 | 576 | - |
| 텐서 코어(TFLOPS) | 130 TFLOPS | 285 TFLOPS |
| VRAM | 24GB GDDR6 | 24GB GDDR6X |
| 가격 | $2,499 | $1,499 |
3090의 텐서 코어의 갯수에 대해서는 정확하게 찾기가 어려워서 초당 부동소수점 연산량의 단위인 FLOPS를 이용하여 비교했습니다.
가격과 성능을 생각했을때, 딥러닝 연구자들에게 3090은 충분한 메리트가 있어 보입니다.
3. NVLink 지원 범위 변경

멀티 GPU를 사용하면서 문제가 되는 부분은 PCIe의 느린 대역폭으로 인한 병목 현상입니다.
그래서 Nvidia는 이를 어느 정도 해결하고자 NVLink라는 개념을 만들었는데요.
NVLink 브릿지, 혹은 NVSwitch를 사용하여 GPU들 간의 고속의 전용 버스를 만들어서 PCIe를 느린 속도를 해결려고 했습니다.
딥러닝 시스템의 경우 GPU의 연산이 주로 많이 사용되므로 성능 향상을 위해서 멀티 GPU를 사용하는 일이 많고, 따라서 NVLink 같은 기술을 활용하여 병목 현상을 최소화하는 것이 좋습니다.
NVLink 같은 기술들은 적용할 수 있는 그래픽카드 라인업이 제한되어 있었습니다.
전 세대를 기준으로 20 라인은 2080 이상, 20 Super 라인은 2070 Super 이상만 제한적으로(NVLink Way 수) NVLink를 지원하였습니다.

하지만, 이번 RTX 30 시리즈부터는 RTX 3090부터 NVLink를 지원합니다.
이 부분에 대해서 어떤 공식적인 발표를 따로 한 것으로 보이지는 않지만 이유를 유추해보면 이렇습니다.
- 어짜피 NVLink를 쓸 사람들은 하이엔드 라인업에서 여분의 성능을 필요로 하는 사람들이기 때문에 하위 라인업에서의 지원은 불필요하다.
- NVLink로 GPU를 엮을 경우 성능적으로 가장 와닿는 부분은 VRAM 일텐데 3080 두장을 연결해도 3090보다 VRAM이 적다. 그리고 그렇게 했을 경우 3080 2장 + NVLink Bridge까지 사면 3090이랑 가격이 비슷해지는데, 일반적으로 그래픽카드에서 성능은 '1+1 = 2'가 되지 않는다는 점을 고려할 때 3080으로 NVLink를 하는 것은 가격적으로나 성능적으로나 심지어 전력 소비면으로나 메리트가 적다고 볼 수 있다.
- 사실 일반인의 입장에서는 NVLink에 대해 별로 관심도 없고, 크게 필요하지도 않다.
대학교 랩처럼 금전적인 여유가 넉넉하지 못한 상황에서는 RTX 2080 Ti로 멀티 GPU를 많이 구성을 했었고, 금전적으로 여유가 된다면 Titan RTX로 구성했던 것으로 알고 있습니다.
RTX 2080 Ti가 $1,199의 가격을 가지고 있는 반면에 3090은 $300 증가한 $1,499의 가격을 가지기 때문에, 멀티 GPU로 구성할 경우 총 예산에서는 차이가 많이 날 수도 있겠지만 증가한 성능(특히 VRAM)을 생각하면 앞으로 3090을 이용한 딥러닝 시스템도 많이 볼 수 있을 것 같다는 생각이 드네요.
4. NVidia RTX IO
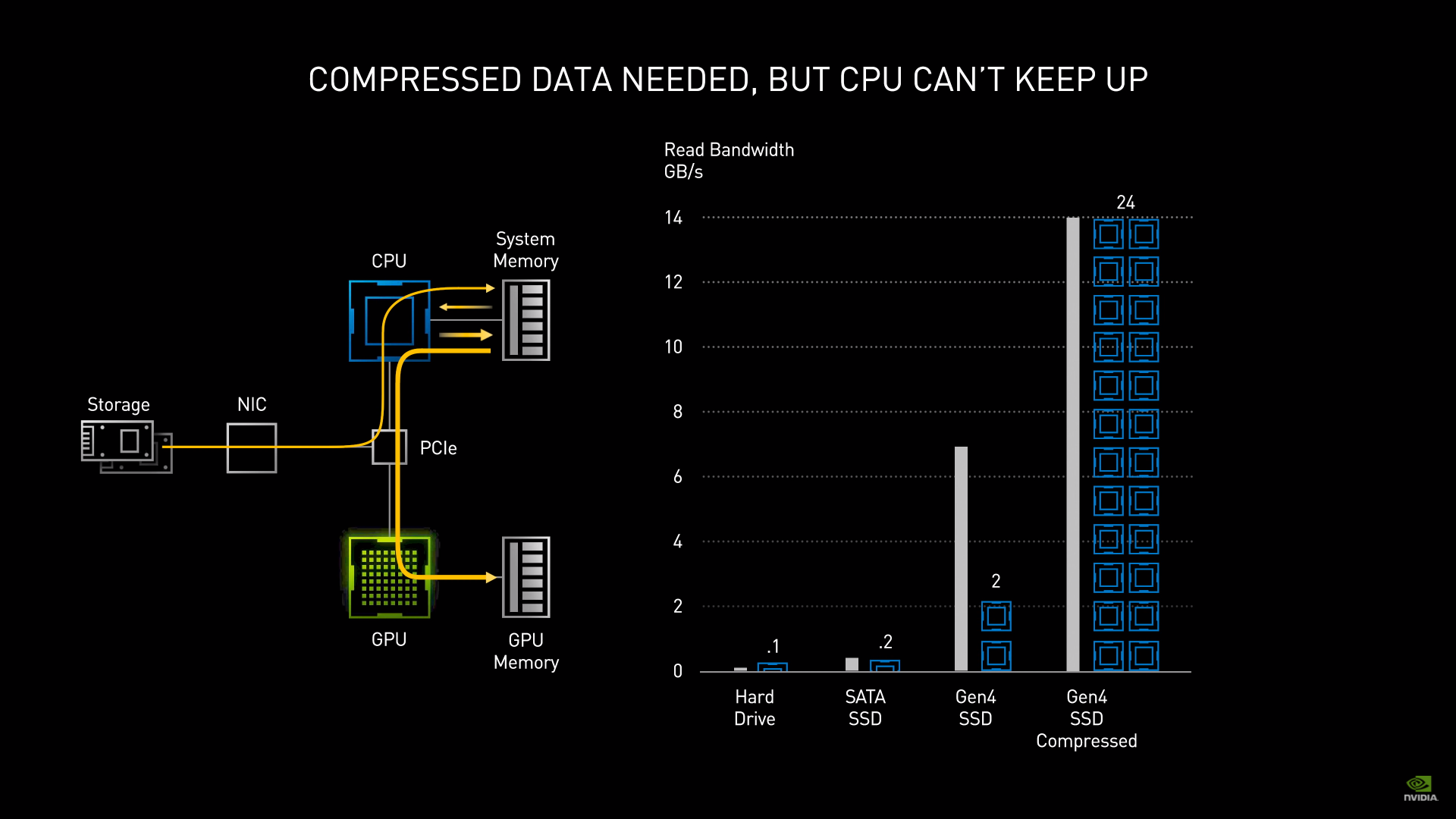
CPU 중심의 컴퓨팅 방식에서 GPU 중심의 컴퓨팅 방식으로 넘어오면서 항상 문제가 되는 부분이 있습니다.
바로 병목현상인데요.
실제로 연산은 그래픽카드가 하더라도 [스토리지 - 메모리 - GPU]로 가는 길목에 CPU가 개입하게 되는데 그 개입만큼 병목현상이 일어납니다.
이 발표 자료에서 말하는 내용은 PCI의 속도가 빨라지면서 대역폭의 속도를 처리하려면 많은 CPU 코어가 필요하게 되었다는 내용입니다.
이번에 새로 발표한 RTX IO는 이러한 점을 어느 정도 해결할 수 있을 것으로 보입니다.
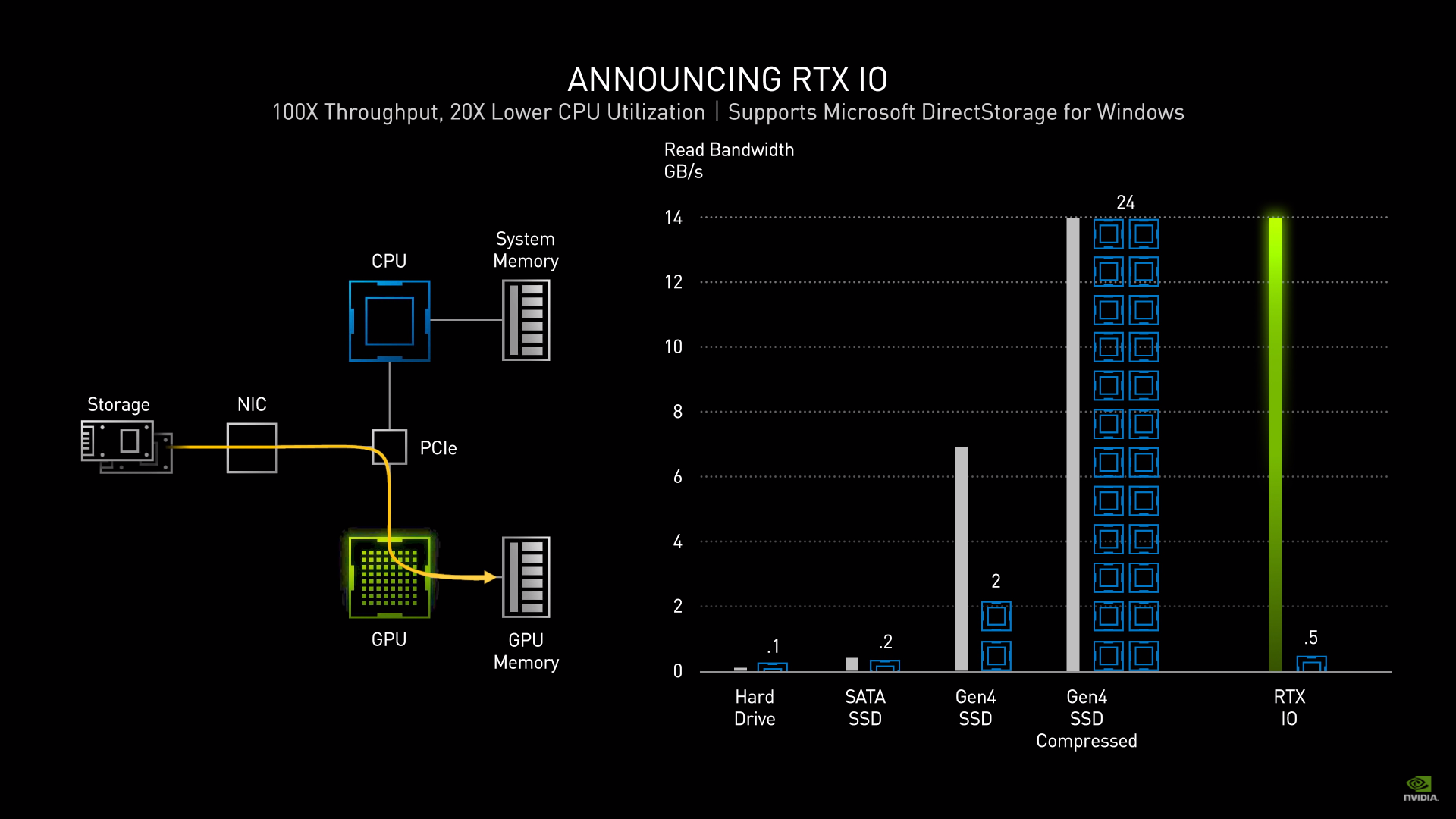
Microsoft와의 협업을 통해 GPU에서 바로 스토리지의 데이터를 사용할 수 있도록 하겠다는 내용입니다.
위에 작은 글씨를 보면 100X Throughput, 20X Lower CPU Utilization이라고 되어 있는데 이 내용대로면 데이터 로딩에 있어서 걸리는 많은 시간들을 단축시켜 줄 수 있을 것 같습니다.
발표에서는 게임 분야에 대해서만 언급했지만, 딥러닝에 접목한다면 병목 현상을 어느 정도 해소할 수 있지 않을까 기대해봅니다!
5. 마무리
현재 RTX 2070 Super 모델을 사용하고 있는 유저의 입장에서 조금은 배가 아픈 발표기도 했습니다..ㅠㅠ
그만큼 RTX 30 시리즈가 잘 나와줬다는 말이기도 할 거 같은데요, 어쩌면 AMD에서 출시하게 될 빅나비를 의식했을지도 모르겠습니다.
원래 한세대는 거르는 게 맞지만... 3090은 너무도 탐나는 기어인 거 같네요..ㅎㅎ
이 외에도 발표에서 나온 내용들은 많으니까 요약본을 보시고 싶으시다면 제가 자주 즐겨보는 가젯서울님의 유튜브 영상을 참고하시면 좋을 것 같습니다!
감사합니다!
